Im letzten Beitrag haben wir kurz vorgestellt, wie wir Infrastruktur in Azure via Azure ARM und Azure CLI bereitstellen können. Dieses Vorgehen wird als Infrastructure as Code (IaC) bezeichnet.
Dabei mussten wir feststellen, dass trotz einheitlicher Skripte bestimmte Parameter mehrfach angegeben werden müssen. Gerade die Eingabe des SQL Admin Passworts ist umständlich, fehleranfällig und für den Produktivbetrieb letztendlich ungeeignet. Darüber hinaus benötigt man zum Ausführen der Skripte die erforderlichen Rechte.
Aus diesem Grund nutzen wir Azure DevOps, früher bekannt als Visual Studio Online (VSO) oder auch Visual Studio Team Service (VSTS). Azure DevOps hat neben verschiedenen Pipeline Arten ….
Erstellen der Release Pipeline
Wir werden für unser Beispiel einzig die Release Pipelines verwenden. Diese Art beruht ursprünglich auf vorangegangenen Build Pipelines und deren Artefakte. Vereinfacht werden wir direkt auf das entsprechende GitHub zugreifen und dessen Skripte nutzen.
Dafür Links die Option Artifacts –> Add wählen, dann das entsprechende GitHub Repository wählen. Weiter muss ein Default Branch gewählt werden. Dieser ist wichtig, um in nachfolgenden Schritten durch das Repository navigieren zu können, kann jedoch für jedes Release geändert werden.


Ebenfalls ist es möglich, einen Continuous Deployment (CD) Trigger zu installieren. Ob es für IaC sinnvoll ist, ist immer abhängig von den konkreten Anforderrungen an die IaC Skripte. Es kann durchaus Sinn ergeben, dass während der Entwicklung der Skripte, regelmäßiges Ausführen zur besseren Qualität beitragen kann, um Fehler frühzeitig aufdecken zu können.



Zuerst müssen wir eine Stage anlegen und uns für einen Namen entscheiden. Wir legen eine leere (empyte) Stage an und wählen die Bezeichnung dev. Da wir planen Shell Skripte auszuführen, ist es aktuell notwendig, aus dem Agent Pool einen Linux Agent zu wählen. Andernfalls kann es zu seltsamen Fehlermeldungen kommen, wie z.B. das File deploy.sh kann nicht gefunden werden.


Setup for SQL Azure Deployment
Nachdem die Stage erstellt wurde, müssen wir einen entsprechenden Azure CLI Task hinzufügen. Dabei ist es unwichtig, ob wir Azure CLI commands direkt absetzen oder Skripte ausführen wollen.

Bevor wir den Task fertig konfigurieren können, sollten wir kurz überlegen, welche Parameter für die Ausführung des Skripts deploy-sql.sh im Ordner SQLAzure notwendig sind. Da wir versuchen möglichst viel über die Pipeline bestimmen zu können, benötigen wir dafür nachfolgende Parameter.
- Database Server Name (SqlDataBaseServerName)
- Database Name (SqlDataBaseName)
- Resource Group Name (ResourceGroupSql)
- Sql Environment (sqlenv)
- Sql Admin Password (SqlPassword)
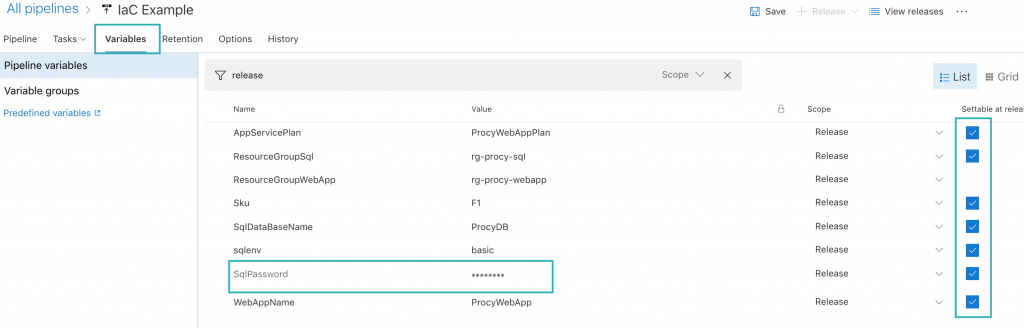
Die Bezeichnungen in den Klammern entsprechen den Variablenbezeichnungen, die wir unter der Rubrik bzw. dem Reiter Variables konfigurieren und bei Ausführung unserer Skripte verwenden können (siehe Abbildung unten). Da ebenfalls die WebApp deployt werden soll, sind die Bezeichnungen ebenfalls dort zu sehen.
Ebenso kann durch die Checkbox am rechten äußeren Rand definiert werden, ob der Wert je Release änderbar ist oder nicht. Das ist natürlich sinnvoll, da wir dann nicht für jedes Feature eine eigene Stage anlegen müssen. Weiter kann das SQL Password als Secret hinterlegt werden.
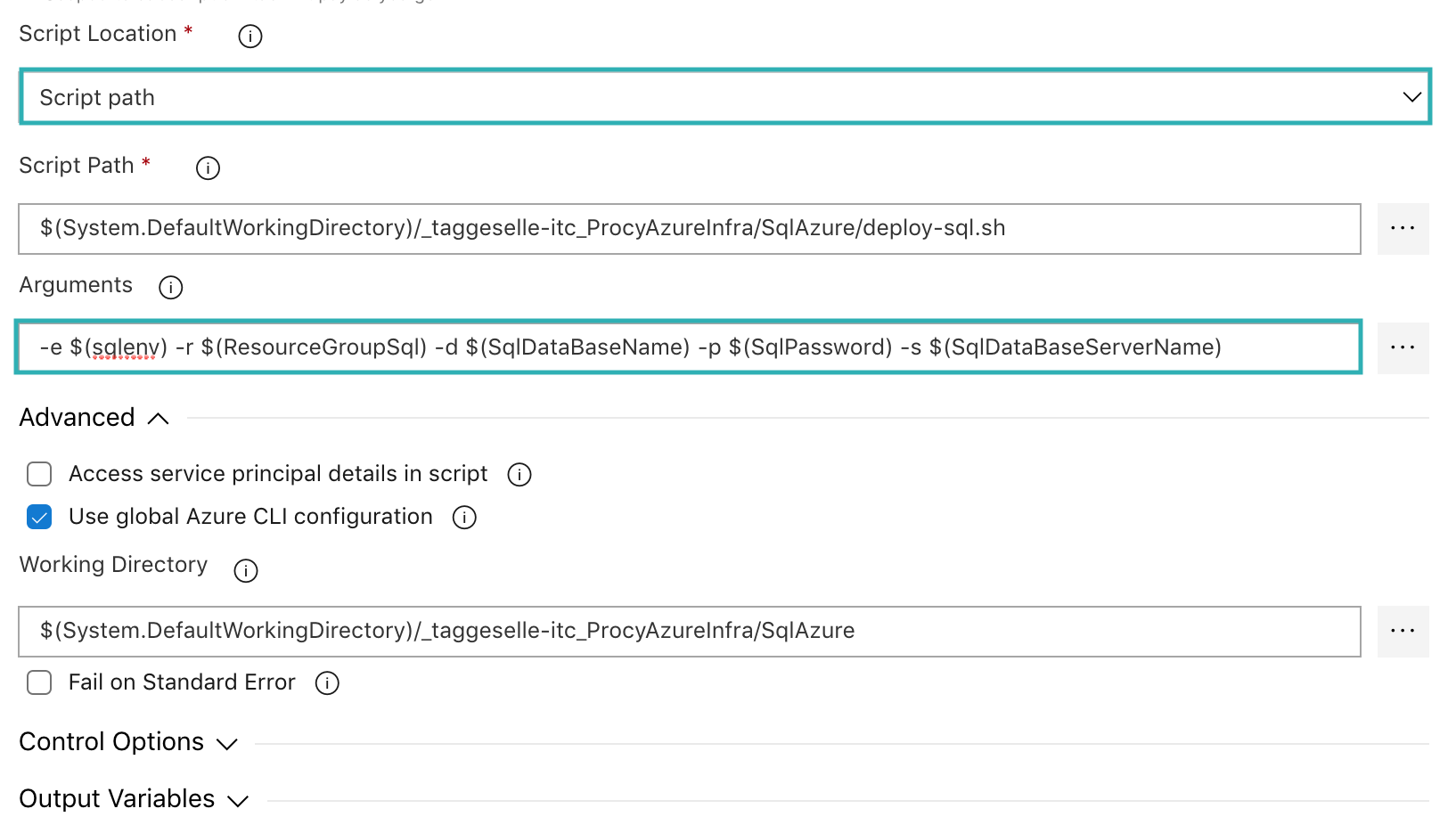
Nachdem wir nun alle notwenigen Variablen definiert und mit Default Werten versehen haben, springen wir zurück zu unserem Azure CLI Task. Die Option Script Location müssen wir auf Script Path stellen, danach kann unter dem Feld Script Path ein Skript gewählt werden (andernfalls wird ein Inlinescript verlangt). Für unser Sql Beispiel, wählen wir das Skript deploy-sql.sh im Ordner SQLAzure. Abschließend müssen wir unter Arguments folgende Zeile hinzufügen.
-e $(sqlenv) -r $(ResourceGroupSql) -d $(SqlDataBaseName) -p $(SqlPassword) -s $(SqlDataBaseServerName)
Anzumerken ist, dass das Working Directory ebenfalls auf den Ordner SQLAzure gestellt ist. Die komplette Konfiguration des Tasks sollte dann wie folgt aussehen.
Auf Grundlage des Setups könnten wir ein neues Release anlegen, die Variablen, falls gewünscht, ändern und das Deployment starten. Wir werden jedoch erst das Setup für die WebApp fertig stellen, bevor wir deployen.
Setup für Azure WebApp Deployment
Das Setup für die WebApp erfolgt analog zum Setup der SQL Azure Datenbank. Wir müssen einen weiteren Azure CLI Task anlegen, die notwendigen Variablen definieren, das WebApp Shell Skript wählen und die Skript Argumente hinzufügen. Die notwendigen Variablen sind nachfolgend aufgelistet.
- App Service Plan Name (AppServicePlan)
- Web App Name (WebAppName)
- Web App Sku (Sku)
Nachdem wir das Skript deploy-webapp.sh im Ordner WebApp gewählt haben, müssen noch die notwendigen Argumente übergeben werden. Die Zeile sollte dann wie folgt aussehen.
-r $(ResourceGroupWebApp) -d $(SqlDataBaseName) -p $(SqlPassword) -f $(AppServicePlan) -a $(WebAppName) -u $(SqlDataBaseServerName)
Verzichten wir auf die Übergabe von bestimmten Argumenten, werden die definierten Default Werte verwendet. Da wir die SQL Credentials schon für das Erzeugen der Datenbank verwendet haben, können wir diese hier ebenfalls für die Übergabe des Connectionsstrings verwenden.
Release deployen
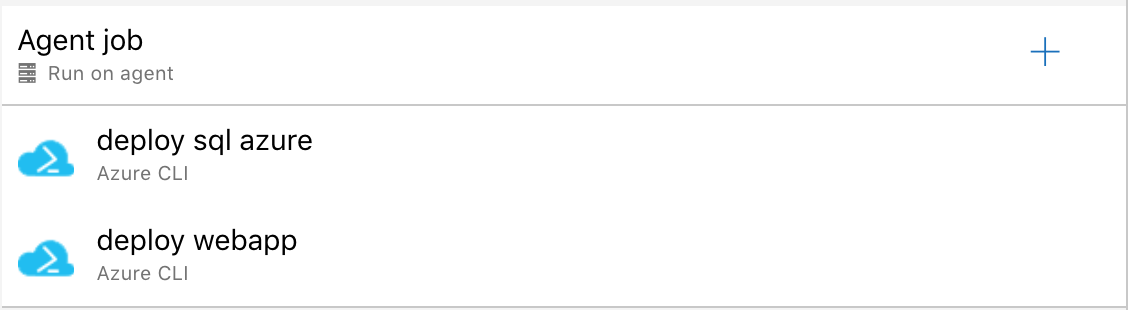
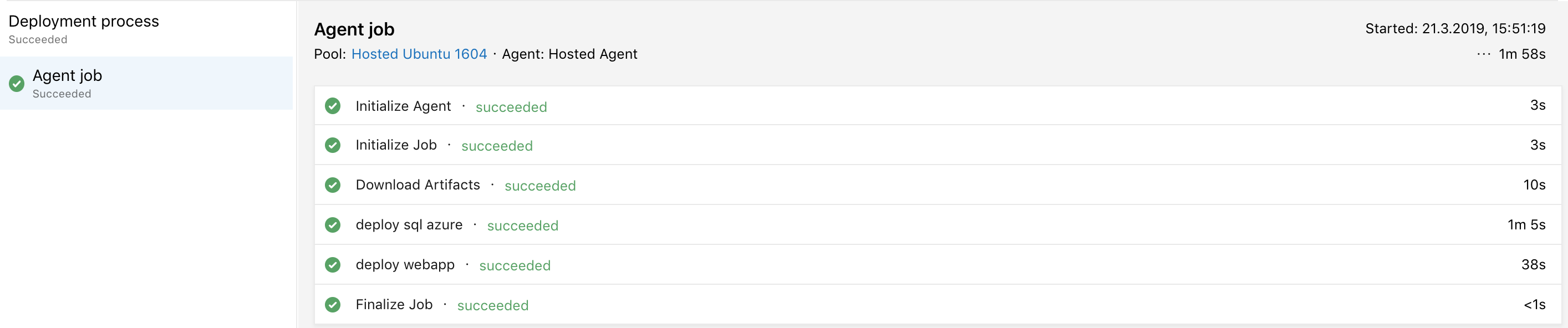
Nachdem beide Tasks angelegt wurden, können wir ein neues Release erstellen und deployen. Konnte der Vorgang erfolgreich abgeschlossen werden, können wir im Azure Portal beide Resource Groups genauer betrachten. Wichtig hierbei ist, dass der hinterlegte Connectionstring in der WebApp mit den Credentials der Datenbank übereinstimmt.
Variablen ändern
Bisher haben wir mit dem eben erstellten Release lediglich die gleichen Ressourcen angelegt, die wir auch ohne die Verwendung von Azure DevOPs erzeugen konnten. Weiter oben wurde kurz erwähnt, dass Variablen ebenfalls je Release geändert werden können. Möchten wir für die Entwicklung eines neuen Features Feature XYZ eine neue Infrastruktur anlegen, benötigen wir genau zwei Dinge: eine neue Datenbank und eine weitere WebApp. Alle anderen Ressourcen und Resource Groups können und sollten weiter bestehen bleiben.
Wir müssen somit lediglich ein neues Release erstellen und die notwendigen Ressourcen erzeugen. Bevor ein Deployment startet, können wir die Variablen ändern, die pro Release als änderbar definiert wurden. Für unser FeatureXYZ könnte es wie folgt aussehen.
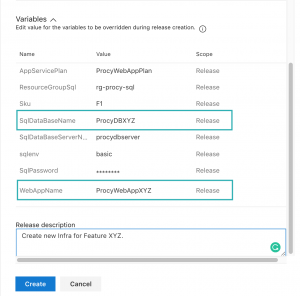
Starten wir nun das Deployment, sollten wir nach erfolgreichem Abschluss die neuen Ressourcen innerhalb der Resource Groups sehen. Ebenfalls muss der Connectionstring, welcher in den App Settings der neuen App ProcyWebAppXYZ hinterlegt ist, zu der eben erstellten Datenbank passen.
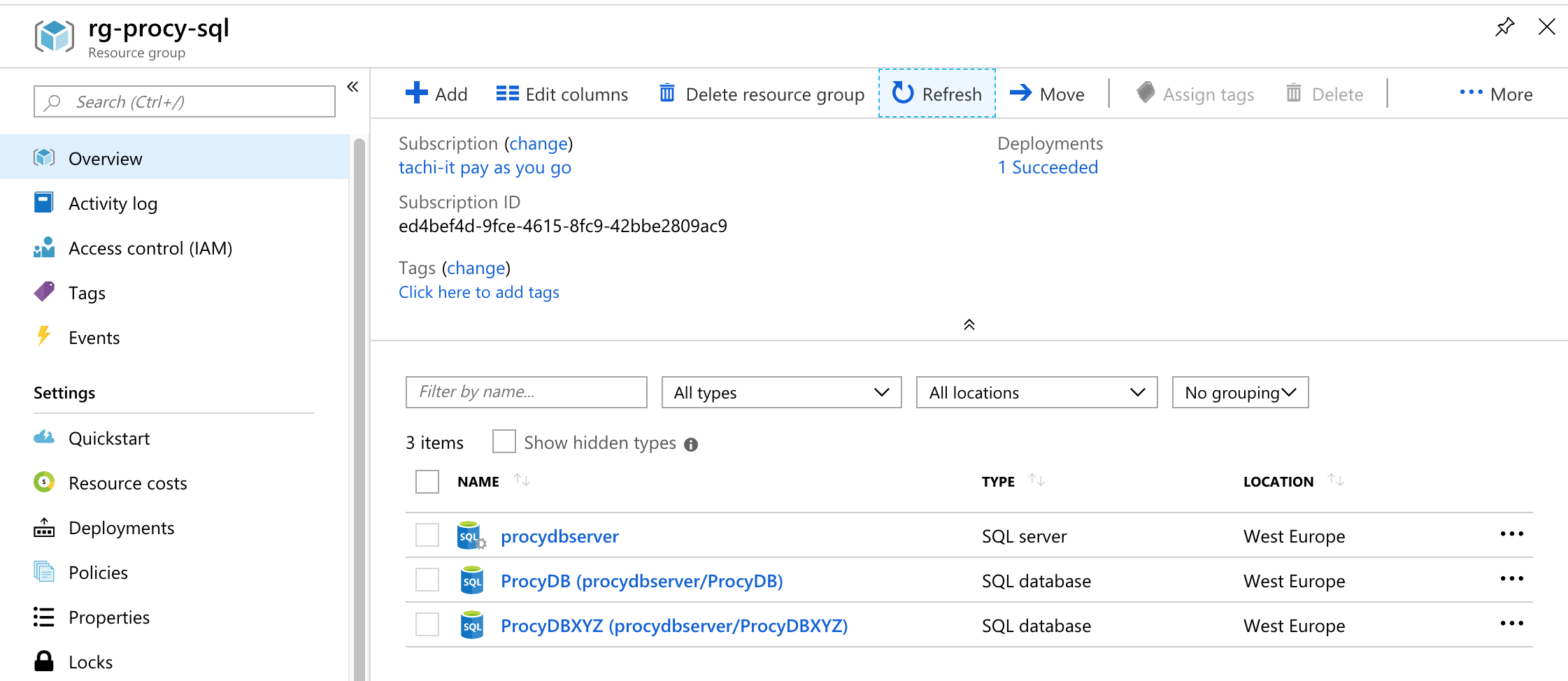
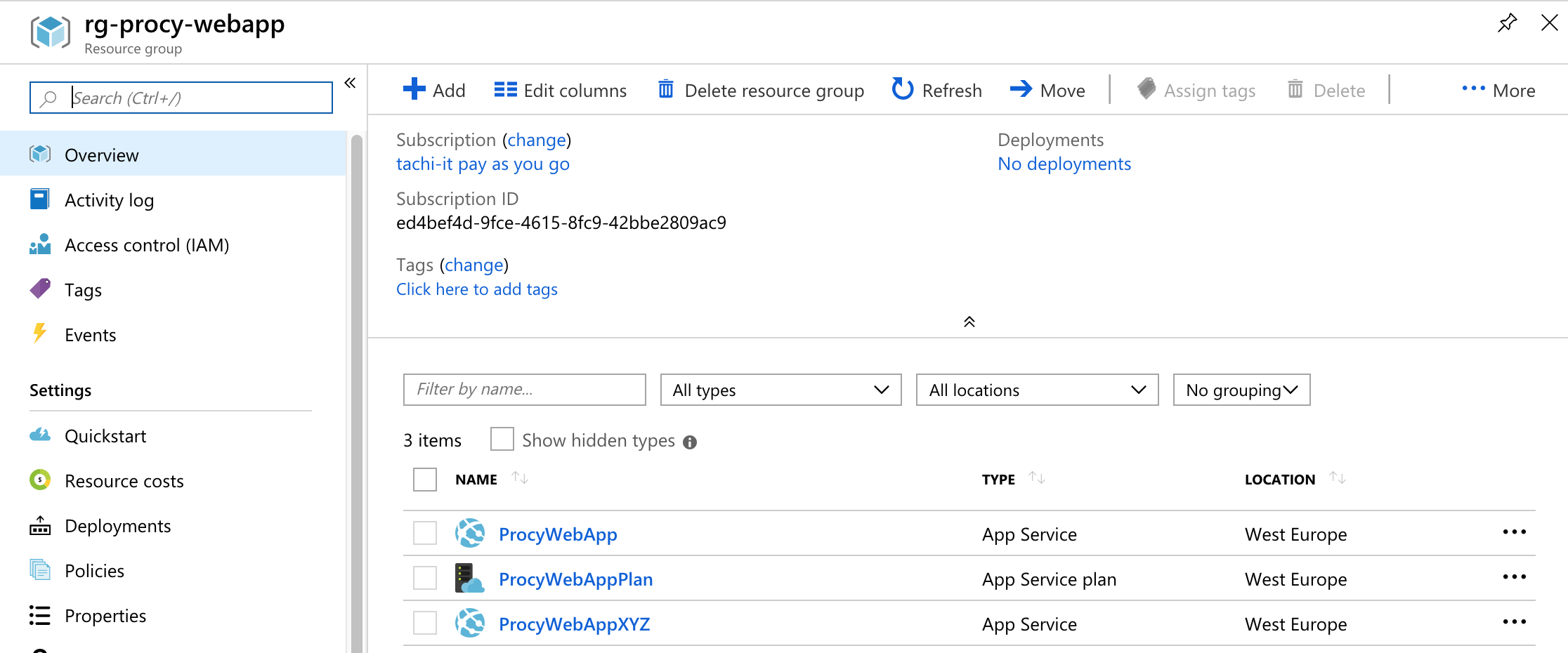

Weiteres Environment
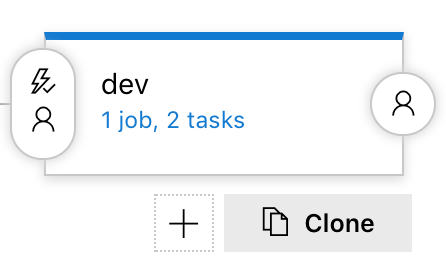
Benötigen wir ein ganz neues Environment z.B. für einen Kunden, der Feature testen möchte, dann kann das erreicht werden, indem wir die aktuelle Stage klonen. Nachdem wird die Stage geklont haben, vergeben wir einen neuen Namen (new-customer). Weiter möchten wir nicht, dass das Deployment automatisch mit einem neuen Release beginnt. Dafür müssen wir die Pre-Deployment condition auf manuell stellen.

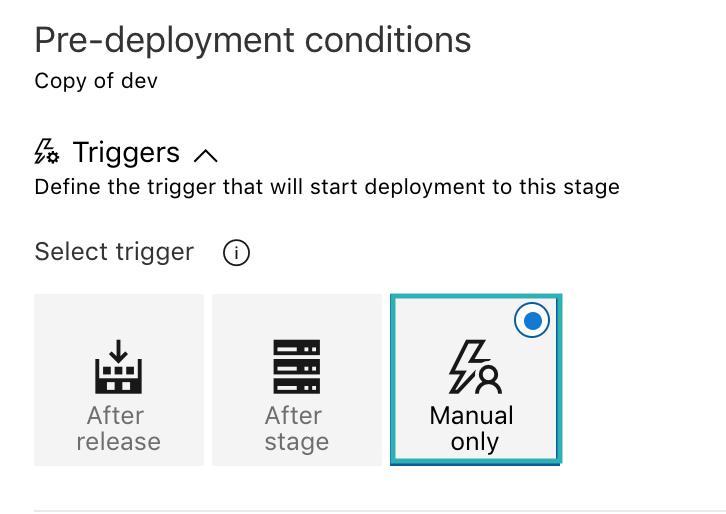
Für ein neues Environment müssen wir mindestens die nachfolgenden Variablen neu definieren, da diese eindeutig sein müssen. Da wir das nicht für jedes Release machen möchten, werden wir das über die Variablendefinition ändern.
- ResourceGroupSql
- ResourceGroupWebApp
- SqlDataBaseServerName
- SqlPassword
- WebAppName
Dafür springen wir zum Tab Variables und legen die oben aufgelisteten Variablen erneut an. Für jede Variable müssen wir den Scope (rechts) ändern, setzen diesen auf new-customer.

Dadurch wird erreicht, dass beim Deployen der Stage new-customer immer genau die definierten Werte genommen werden. Das Ergebnis sollte dann wie folgt aussehen.
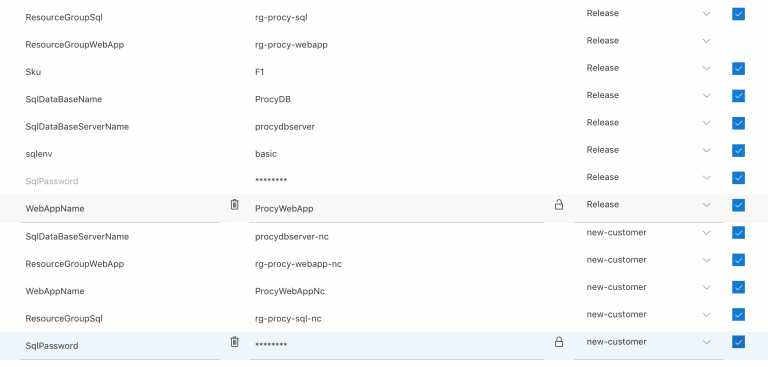
Bei der Fülle an Variablen kann dieser Weg schnell unübersichtlich werden. Dann wäre es wahrscheinlich besser, einfach einen Prefix bzw. Suffix oder ähnliches zu definieren, der je Environment also Scope Variable gesetzt wird.
Erzeugen wir nun ein neues Release und deployen die new-customer Stage, sollten wir zwei neue Resource Groups inkl. neuen Ressourcen finden. Auch hierbei sollte der Connectionstring in den App Settings geprüft werden. Die URL muss zum neu erstellen Datenbankserver passen.
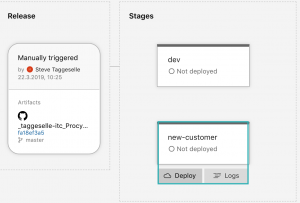
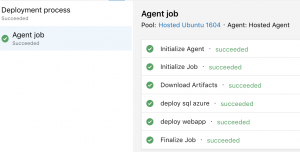
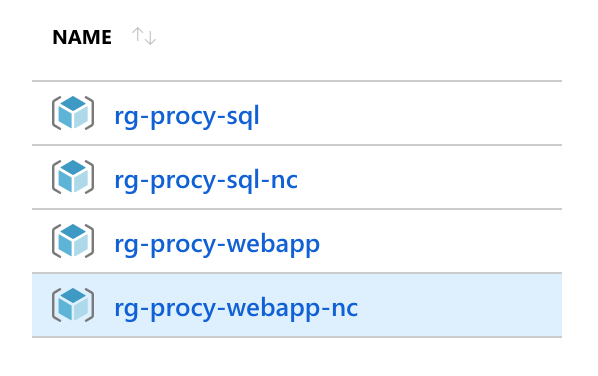
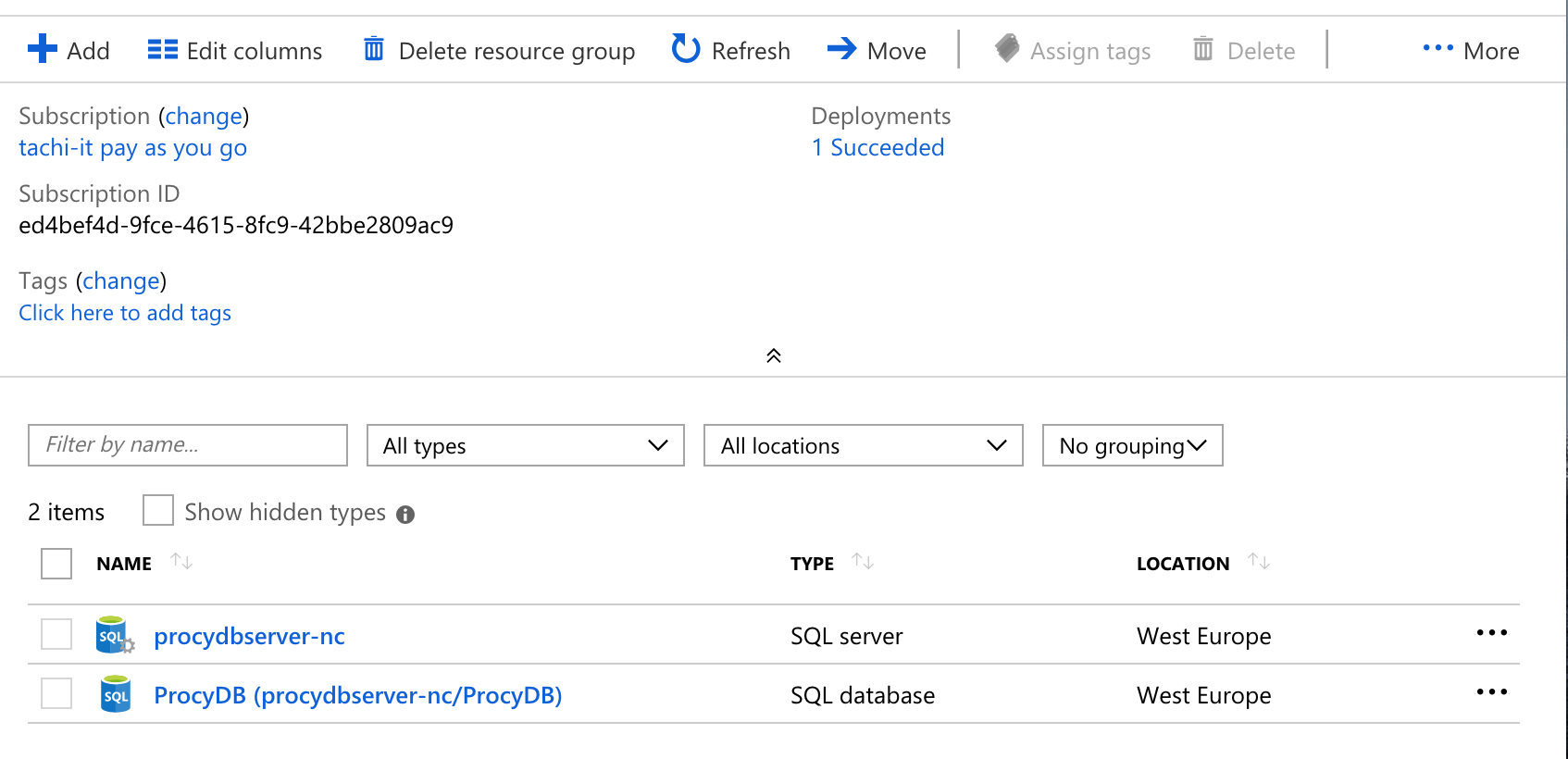
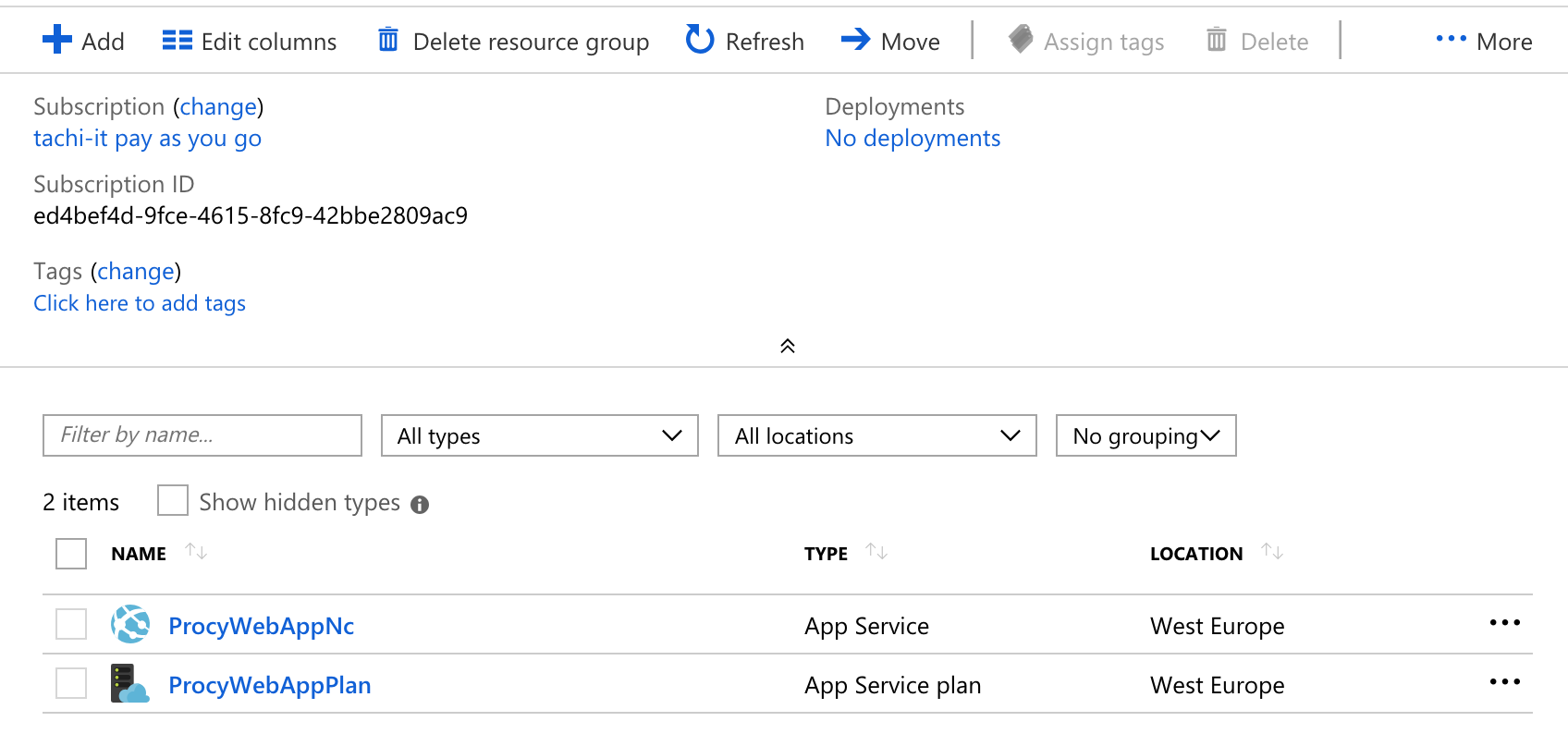
Durch das Erzeugen einer neuen Stage und die Verwendung der Scopes in der Variablendefinition kann sehr schnell ein komplett neues Environment aufgesetzt werden. Auch dieses kann als Grundlage zur Feature Entwicklung dienen.
Anmerkung
Mit einer leeren Datenbank, lässt sich natürlich nur schwer etwas präsentieren bzw. reviewen. Die Software kann zwar schnell in der Web App deployed werden, die Datenbank würde nicht zur App passen. In bestimmten Fällen muss man auf ein Backup zurück greifen. Wir verwenden dafür Migrationsskripte, die ausgeführt werden müssen und anschließend noch ein paar Beispieldatensätze anlegen.
Für die Ausführung dieser Skripte, würden wir wieder den Connectionstring benötigen, was aktuell nur durch Kopieren möglich wäre. Wir verwenden für solche Szenarien einen oder mehrere Azure Key Vaults, deren Secrets dann als Variable Group’s in Azue Dev Ops eingebunden werden. Dadurch muss das Passwort nur einmal angegeben und kann in verschiedenen Piplines verwendet werden.
Zusammenfassung
In diesem Beitrag konnten wir auf Grundlage unserer Deployment Skripte den Automatisierungsgrad dank Azure DevOps weiter erhöhen. Wir konnten sowohl neue Services für die Feature Entwicklung als auch komplett neue Umgebungen erzeugen. Solche Umgebungen könnten beispielsweise für Lasttests, indem die produktionsnahen Sku’s gewählt werden, dienen. Ebenfalls können sie zu Präsentationszwecken verwendet werden.